Building a Scalable Streaming Architecture with Kafka and Debezium for Multiple SQL Databases

In a recent project at work, we needed to monitor changes to data stored in multiple databases and services in real-time. To achieve this goal, we opted for Kafka as our distributed streaming platform. We chose Confluent Cloud, the hosted service provided by the creators of Kafka, for our Kafka Cluster as it offers a fully managed Kafka Service, eliminating the need for us to handle infrastructure management, scaling, or maintenance tasks. However, when it came to implementing Change Data Capture (CDC) to capture changes from our databases, we faced a challenge. Our databases follow a single tenancy isolation strategy, which means that each tenant has their own isolated database instance. We have hundreds of tenants, each with their own database, which would require hundreds of Debezium connectors in a typical setup.
Confluent Cloud offers a managed solution for CDC through its connectors, but the pricing model would not be favorable for our setup with hundreds of connectors. So, we had to come up with a solution that would work with our unique architecture and budget constraints. We ended up deploying self-managed Kafka Connect Instances in Azure Kubernetes Cluster
Here is the overall streaming architecture:
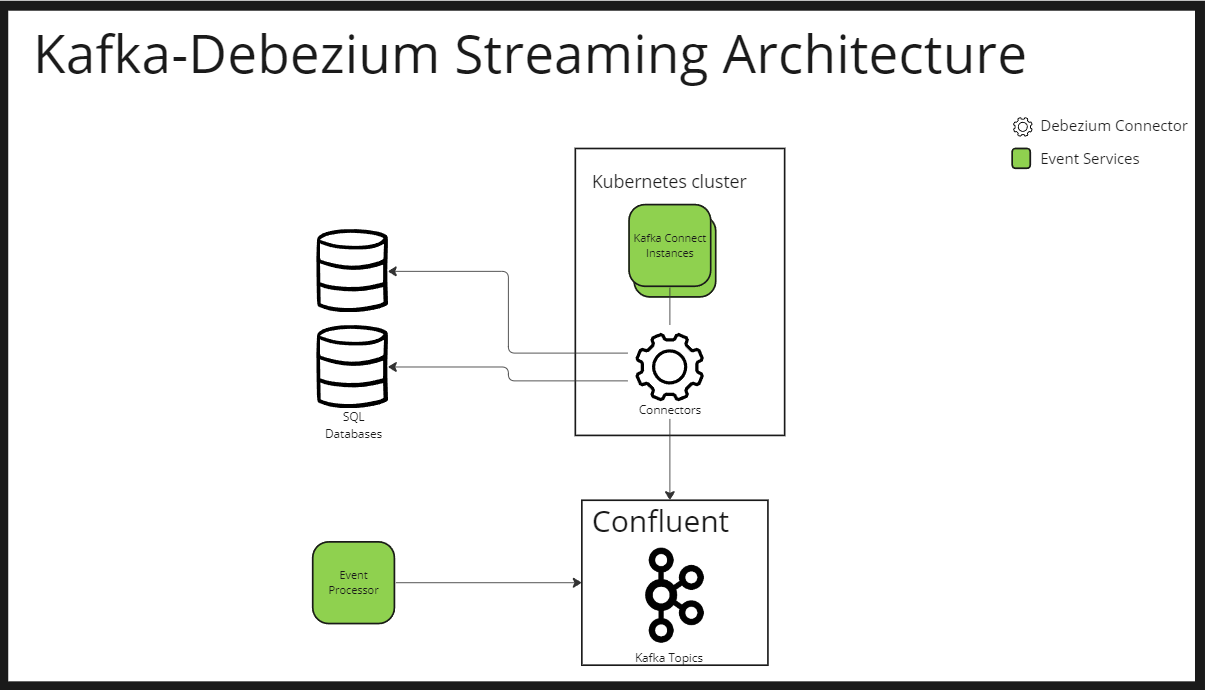
Some service updates the SQL database
The debezium connector, registered in Kafka Connect Instance deployed in Kubernetes environment, captures the changes
Debezium worker sends the events to confluent Kafka raw topic
The event processor processes the event and pushes that to another final topic for consumption
Why Kafka?
Kafka is a powerful distributed streaming platform that enables users to build scalable and reliable data pipelines and applications. It is based on the publish-subscribe messaging model and allows producers to publish messages to a Kafka topic, while consumers subscribe to the topic to receive messages. With its high throughput, low latency, and fault-tolerant architecture, Kafka is widely used for building real-time data streaming pipelines.
One popular use case for Kafka is Change Data Capture (CDC), which is the process of detecting and capturing changes to data sources and making those changes available in real-time to other systems or applications. This is where Debezium comes in. Debezium is an open source distributed platform that provides change data capture capabilities for Kafka. With Debezium connectors, Kafka can capture data changes from various data sources such as MySQL, PostgreSQL, MongoDB, and Oracle, among others (MSSQL in our case).
Deploying Debezium Connectors
Deploying Debezium connectors on a self-managed Kubernetes cluster was not an easy endeavor. Deploying a self-managed service does require more effort in terms of setting up and maintaining the cluster. Specially for someone who had not deployed any Kubernetes service before! But open source came to the rescue.
To deploy the Debezium connector on a self-managed AKS cluster we used the open-source Strimzi operator. Strimzi provides an easy and scalable way to manage Kafka and Kafka Connect clusters on Kubernetes. It allows for the deployment of Kafka brokers, ZooKeeper nodes, Kafka Connect workers, and Debezium connectors as Kubernetes resources. Strimzi also enables the configuration and scaling of Kafka and Kafka Connect resources using Kubernetes Custom Resource Definitions (CRDs). For our use case, we only needed to deploy Kafka Connect and Debezium Connectors
Kafka Connect Yaml
To deploy a Kubernetes service, you need to provide a YAML file. For production use cases I would not recommend to kubectl directly but use something like Helm charts (we use helm charts for all our kubernetes deployment). With that out of the way, lets dig into Kafka Connect
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: debezium-connect-cluster
annotations:
strimzi.io/use-connector-resources: "true"
spec:
image: {{ custom-image/kafka-connect-with-x-connector }}
replicas: 2
bootstrapServers: {{ kafka-cluster-kafka-bootstrap:9092 }}
config:
group.id: connect-cluster
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-status
# -1 means it will use the default replication factor configured in the broker
config.storage.replication.factor: -1
offset.storage.replication.factor: -1
status.storage.replication.factor: -1
#secret config
config.providers: secrets
config.providers.secrets.class: io.strimzi.kafka.KubernetesSecretConfigProvider
The ones with {{ }} double braces need to be updated
First is the image, for KafkaConnect. By default base Kafka Connect image doesnot include any connectors. You need to add each one you need to /opt/kafka/plugins/ directory. Please follow deploying debezium with kafka connector for more details. It is quite old but is full of riches. I might write a blog on just the building image part later. The second variable is the bootstrapServers which is where the kafka cluster is. In our case it is the confluent but for local testing, it is {{ your kafka cluster name}}-bootstrap-server:9092. So if you kafka cluster is named "kafka-cluster" it would be kafka-cluster-kafka-bootstrap:9092
To scale all you have to do is increase the replicas value, in the example is 2. Since KafkaConnect is a custom type, provided by Strimzi CRDs, strimzi operator takes care of the rest of the deployment for you. In background, strimzi operator creates one Deployment with RollingUpdate Strategy with x replicas and Kafka Connect environment variables
Installing Kafka Connect
Assuming you have a Kubernetes environment and helm you can apply the yaml file to a specific namespace like 'kafka'. Prerequisite for setting your local environment:
Minikube : Minikube is local Kubernetes, focusing on making it easy to learn and develop for Kubernetes
Helm : Helm helps you manage Kubernetes applications
Hyper-V : Enable Hyper-V on your windows machine, if you are using windows
# create kafka namespace
kubectl create ns kafka
# add strimzi repo to helm chart
helm repo add strimzi https://strimzi.io/charts/
# install strimzi operator
helm install strimzi strimzi/strimzi-kafka-operator --namespace kafka
# deploy kafka connect
kubectl apply -f kafka-connect.yaml --namespace kafka # yaml file shown above
Deploying Debezium Kafka Connector
Next is to deploy the debezium connector. And here is the sample yaml file
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: sql-connector-001
labels:
strimzi.io/cluster: debezium-connect-cluster
spec:
class: io.debezium.connector.sqlserver.SqlServerConnector
tasksMax: 1
config:
database.server.name: {{ server-name }}
database.hostname: {{ host-name }}
database.dbname: {{ $dbname | lower | quote }}
database.user: "${secrets:kafka/dbsecret:username}"
database.password: "${secrets:kafka/dbsecret:password}"
#history events for database changes
database.history.kafka.bootstrap.servers: {{ kafka-cluster-kafka-bootstrap:9092}}
database.history.kafka.topic: schema-changes-topic
#included tables
table.include.list: "dbo.table_1"
column.include.list: "dbo.table_1.id, dbo.table_1.name"
# secret file
apiVersion: v1
kind: Secret
metadata:
name: dbsecret
namespace: kafka
type: Opaque
data:
username: {{ b64encoded username}}
password: {{ b64encoded password}}
# applying secret
kubectl apply -f dbsecret.yaml
# apply connector
kubectl apply -f sql-connector-001.yaml -n kafka
We are using KubernetesSecretConfigProvider in the KafkaConnect chart above. This allows to dynamically load db secrets in kafka connector above with properties:
database.user: "${secrets:kafka/dbsecret:username}"
database.password: "${secrets:kafka/dbsecret:password}"
This allows to add secrets or update them without restarting the Kafka Connect Instance as Debezium connectors are barely configurations attached to KafkaConnect
Conclusion
In conclusion, deploying Kafka Connect and Debezium Kafka Connector can be a great solution for capturing database changes and streaming them to Kafka. With the help of Kubernetes and Helm, deploying and scaling the solution is made much easier. While there are many ways to deploy Kafka Connect and Debezium Kafka Connector, using Strimzi can simplify the process and provide additional features like custom resource definitions for Kafka Connect and Kafka Connector. Additionally, using a fully managed Kafka service like Confluent Cloud can reduce the operational burden and allow you to focus on building your streaming application. With the right setup, deploying Kafka Connect and Debezium Kafka Connector can help you build real-time data pipelines and unlock valuable insights from your data.
I only scratched the surface of deploying Kafka connect and connectors. Please leave comments if you want to learn more about something I failed to mention



